引言
1.1 什么是MQ
MQ(Message Quene) : 翻译为 消息队列,通过典型的 生产者和消费者模型,生产者不断向消息队列中生产消息,消费者不断的从队列中获取消息。因为消息的生产和消费都是异步的,而且只关心消息的发送和接收,没有业务逻辑的侵入,轻松的实现系统间解耦。别名为 消息中间件 通过利用高效可靠的消息传递机制进行平台无关的数据交流,并基于数据通信来进行分布式系统的集成。
MQ有哪些
当今市面上有很多主流的消息中间件,如老牌的ActiveMQ、RabbitMQ,炙手可热的Kafka,阿里巴巴自主开发RocketMQ等。
不同MQ特点
# 1.ActiveMQ
ActiveMQ 是Apache出品,最流行的,能力强劲的开源消息总线。它是一个完全支持JMS规范的的消息中间件。丰富的API,多种集群架构模式让ActiveMQ在业界成为老牌的消息中间件,在中小型企业颇受欢迎!
# 2.Kafka
Kafka是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache顶级项目。Kafka主要特点是基于Pull的模式来处理消息消费,
追求高吞吐量,一开始的目的就是用于日志收集和传输。0.8版本开始支持复制,不支持事务,对消息的重复、丢失、错误没有严格要求,
适合产生大量数据的互联网服务的数据收集业务。
# 3.RocketMQ
RocketMQ是阿里开源的消息中间件,它是纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。RocketMQ思路起
源于Kafka,但并不是Kafka的一个Copy,它对消息的可靠传输及事务性做了优化,目前在阿里集团被广泛应用于交易、充值、流计算、消
息推送、日志流式处理、binglog分发等场景。
# 4.RabbitMQ
RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和
发布/订阅)、可靠性、安全。AMQP协议更多用在企业系统内对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在
其次。RabbitMQ比Kafka可靠,Kafka更适合IO高吞吐的处理,一般应用在大数据日志处理或对实时性(少量延迟),可靠性(少量丢数据)要求稍低的场景使用,比如ELK日志收集。
同步通讯和异步通讯
1.1 同步通讯
同步通讯是指发送方在发送消息后,会等待接收方的回应,直到收到回应后才会继续执行后续操作
同步通讯的特点是:
阻塞:发送方在等待回应期间会被阻塞,无法进行其他操作
顺序执行:消息的处理是按照发送和接收的顺序进行的,确保了消息的时序性
实时反馈:发送方可以立即得到接收方的回应,适用于需要立即确认的场景
占用资源:由于需要等待,可能会造成资源的浪费,如线程阻塞
打电话就是一个典型的同步通讯例子,通话双方必须实时交流,一方说话时,另一方必须等待
异步通讯
异步通讯是指发送方在发送消息后,不需要等待接收方的立即回应,就可以继续执行其他操作。接收方在处理完消息后,可能会在未来的某个时间点给出回应
异步通讯的特点是:
非阻塞:发送方在发送消息后可以立即继续其他工作,不会因为等待回应而被阻塞
解耦:发送方和接收方在时间上解耦,可以独立处理各自的任务
灵活:异步通讯可以处理更复杂的通信模式,如消息队列、事件驱动等
资源利用率高:更高效地利用资源,因为不需要等待,可以提高系统的吞吐量
电子邮件是一个异步通讯的例子,你可以发送一封邮件后继续做其他事情,收件人可以在任何时间回复邮件(微信聊天也是一个异步通讯的例子)
同步调用的缺点
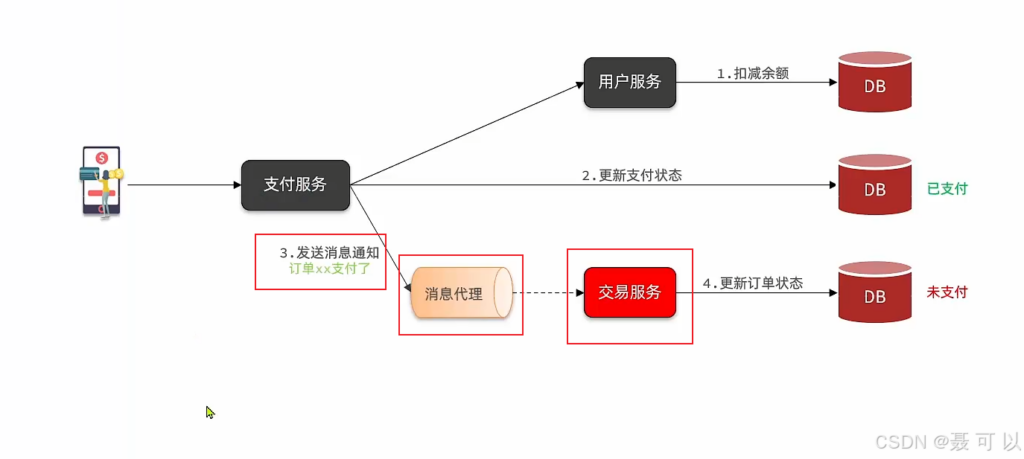
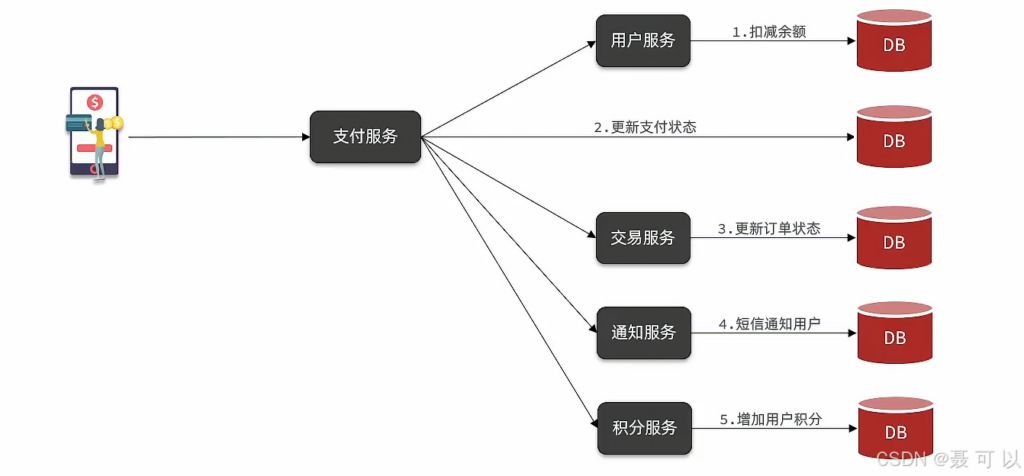
我们以支付业务为例分析同步调用的缺点
支付业务采用的是同步调用的方式,因为我们在执行更新支付状态操作和更新订单状态之前,需要先知道扣减余额操作的结果,这种同步调用方式存在几个问题
业务耦合
第一个问题就是业务耦合的问题,对于支付服务来说,最重要的一件事就是扣减用户的余额,然后更新支付状态
后续的更新订单状态操作跟支付服务是没什么关系的,但是支付成功之后确实需要更新订单状态,所以支付服务不得不调用交易服务来更新订单状态
那有同学就说了,我在支付服务里面加一行代码不就可以调用交易服务了吗,听起来没什么问题,但是业务是会变化的,产品经理的脑洞你也是想象不到的
想象一下,产品经理提了一个新的需求,用户支付成功之后要发一个短信通知用户,产品经理一提需求,我们就要更改源代码
某一天,产品经理又提了一个新需求,用户支付成功之后,要为用户增加一定的积分
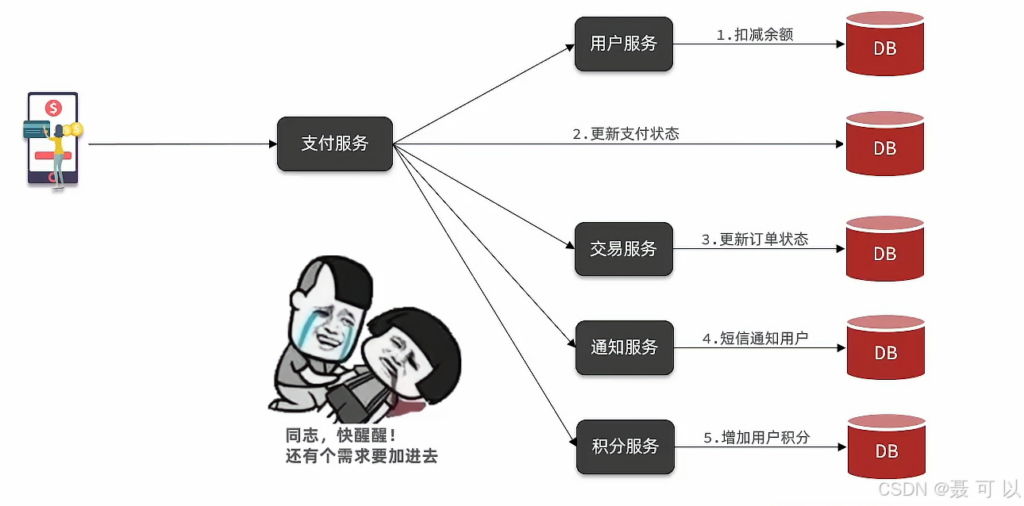
这种同步调用的方式拓展性比较差,不符合面向对象编程中的开闭原则
性能较差
如果采用同步调用的方式,支付服务需要等待其它所有服务完成操作,耗时会大大增长,十分影响用户的体验
3 级联失败
想象一下,交易服务出现故障了,而这个故障迟迟没有得到解决,最终就很有可能拖垮支付服务,导致支付服务的资源被耗尽,也出现故障,出现级联失败的情况、
什么情况下使用同步调用
经过上面的分析,有同学可能会有这样的疑问:既然同步调用有这么多问题,为什么我们还要用同步调用呢,什么情况下使用同步调用呢
一般来说,使用同步调用的场景都有一个特点:下一步操作依赖于上一步操作的结果
以上面的支付业务为例,交易服务、通知服务、积分服务都依赖于支付服务的结果
当支付服务成功扣减用户余额并成功更新支付状态之后,交易服务、通知服务、积分服务就可以开始执行相应的操作了
然而,通知服务不依赖于交易服务,积分服务也不依赖于通知服务
在成功扣减用户余额并成功更新支付状态之后,支付业务就已经完成了
所以说,支付服务完成了之后,只需要通知交易服务、通知服务、积分服务执行相应的操作,而不需要等待交易服务、通知服务、积分服务都完成之后再返回结果
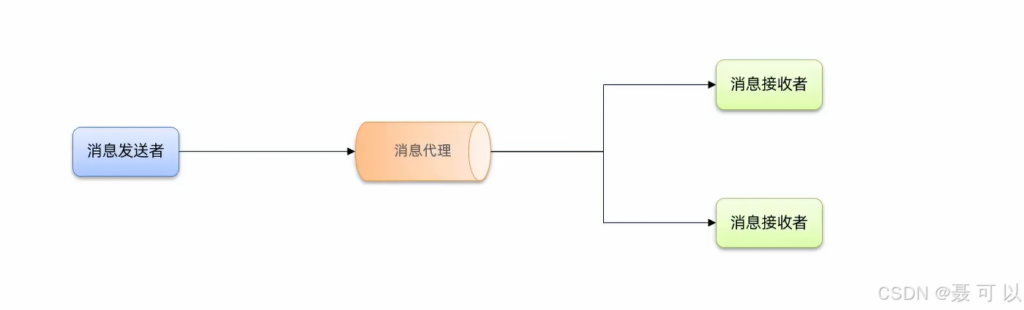
异步调用
异步调用基于消息通知,一般包含三个角色消息
- 发送者:投递消息的人
- 消息代理:管理、暂存、转发消息的人
- 消息接收者:接收和处理消息的人
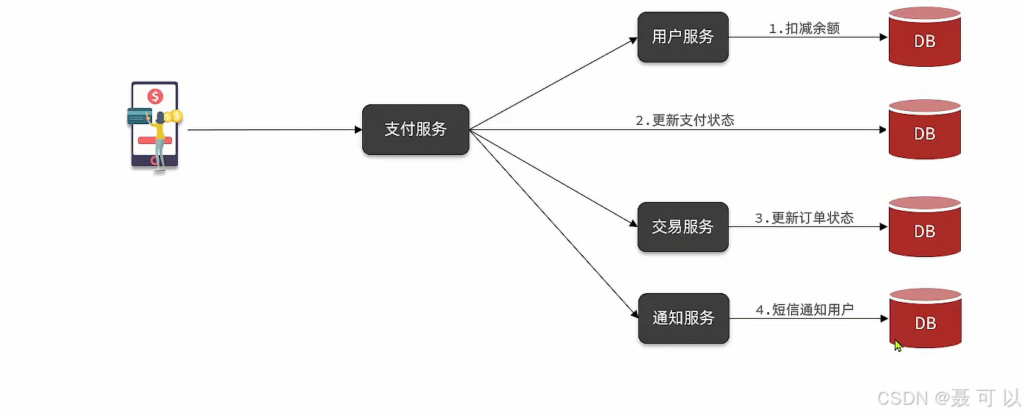
改为异步调用之后,支付服务不再同步调用与支付业务关联度低的服务,而是发送消息通知于支付业务关联度低的服务
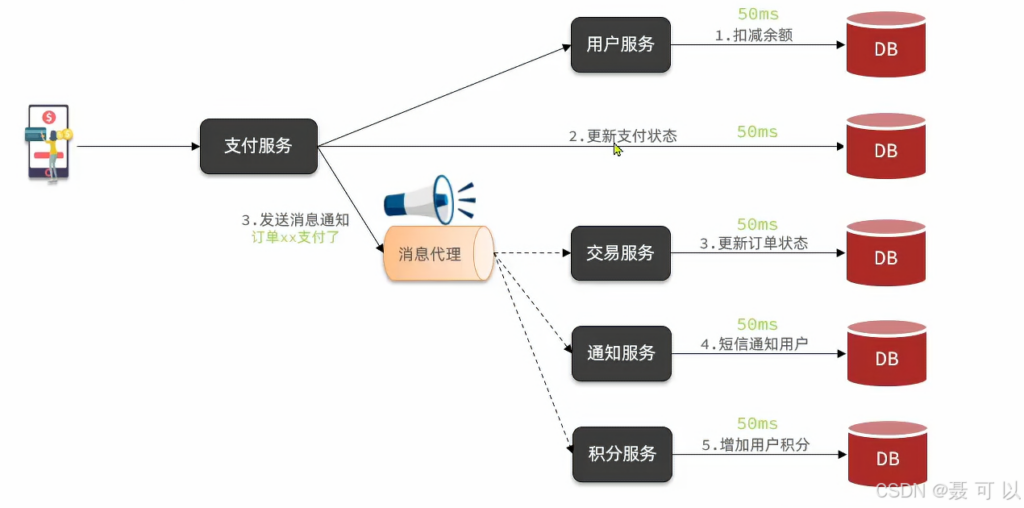
异步调用的优点和缺点
异步调用的优点
解除耦合,拓展性强
即使以后有新业务拓充,支付服务只需要发送一条消息给消息代理,让消息代理通知新业务,拓展性强
无需等待,性能好
支付服务完成之后只需要发送消息给消息代理,让消息代理通知其它服务
故障隔离
即使交易服务出现了故障,也不会影响到支付服务
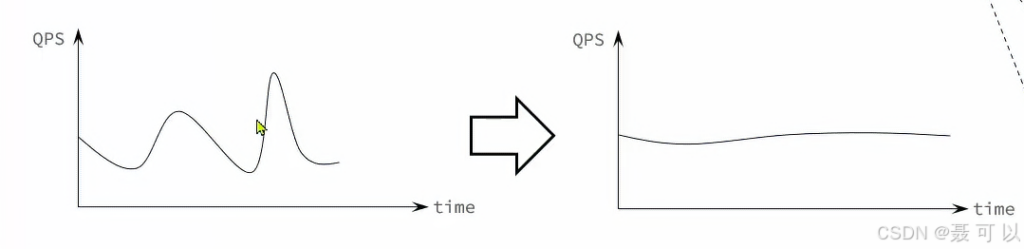
削峰填谷
假如支付服务正在面临着很大的压力,流量时高时低(呈波浪形)。如果采用同步调用的方式,当流量很高的时候,交易服务、通知服务、积分服务可能扛不住
但如果采用异步调用的方式,就很少会出现交易服务、通知服务、积分服务扛不住的情况。为什么呢,因为消息代理容量很大。在高并发的情况下,用户每成功支付一次,支付服务只需要发送一条消息给消息代理,这些像洪水一般的消息都会被消息代理拦住
消息代理会保存这些消息,后续服务可以根据自己的处理速度,从消息代理中一条一条地取出信息并处理。这样一来,后续服务承受的压力将会变得很平缓
异步调用的缺点
不能得到调用结果
异步调用一般是通知对方执行某个操作,无法知道对方执行操作后的结果
不确定下游业务执行是否成功
异步调用通知下游业务后,无法知道下游业务是否执行成功
业务安全依赖于消息代理的可靠性
下游业务的执行依赖于消息代理的可靠性,一旦消息代理出现故障,下游业务将无法执行
RabbitMQ 快速入门
注意事项:交换机只能路由和转发消息,不能存储消息
java客户端入门
新建一个 SpringBoot 项目,并创建 consumer 和 publisher 两个子模块,项目的整体结构如下
引入 Maven 依赖
在父工程中引入 SpringAMQP 的依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>编写与 RabbitMQ 有关的配置信息
在 consumer 和 publisher 模块的 application.yml 中分别编写与 RabbitMQ 有关的配置信息
spring:
rabbitmq:
host: 127.0.0.1
port: 5672
virtual-host: /blog
username: CaiXuKun
password: T1rhFXMGXIOYCoyi
完成一个简单的案例
案例要求如下:
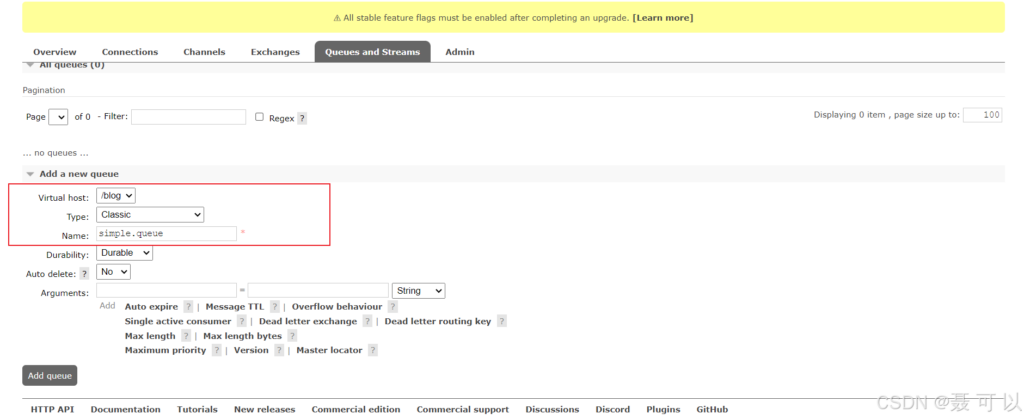
在 RabbitMQ 的控制台中创建名为 simple.queue 的队列(队列归属的 VirtualHost 为 /blog)
在 publisher 模块中,利用 SpringAMQP 直接向 simple.queue 队列发送消息
在 consumer 服务中,利用 SpringAMQP 编写消费者,监听 simple.queue 队列
11.3.1 创建队列
发送消息
在 publisher 模块中编写测试类,用户向队列发送消息
import org.junit.jupiter.api.Test;
import org.springframework.amqp.rabbit.core.RabbitTemplate;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
@SpringBootTest(classes = PublisherApplication.class)
public class SpringAmqpTest {
@Autowired
private RabbitTemplate rabbitTemplate;
@Test
void testSendMessageToQueue() {
String queueName = "simple.queue";
String msg = "Hello, SpringAMQP!";
rabbitTemplate.convertAndSend(queueName, msg);
}
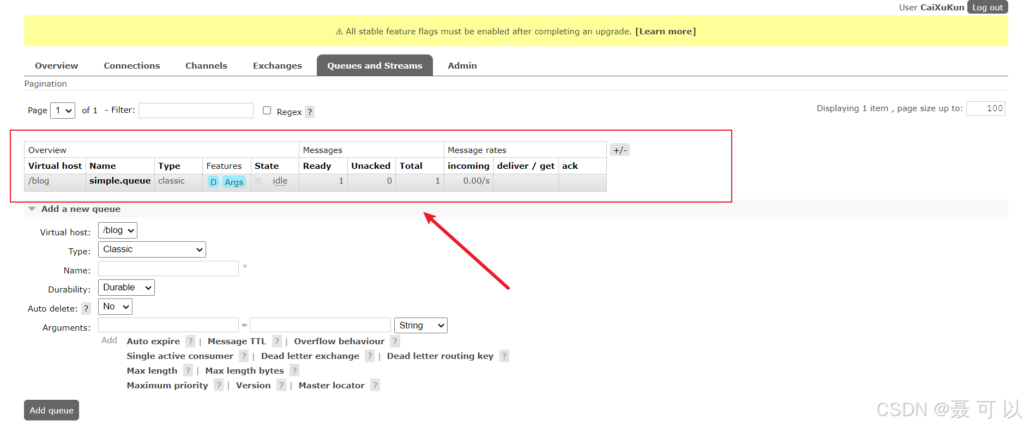
}在 RabbitMQ 的控制台可以看到,消息成功发送
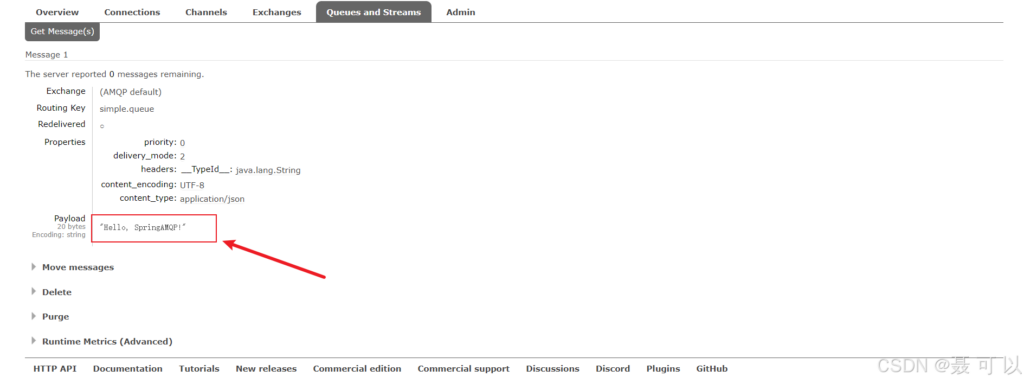
接收消息
SpringAMQP 提供了声明式的消息监听,我们只需要通过@RabbitListener注解在方法上声明要监听的队列名称,将来 SpringAMQP 就会把消息传递给使用了@RabbitListener注解的方法
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.stereotype.Component;
@Component
public class RabbitMQListener {
@RabbitListener(queues = "simple.queue")
public void listenSimpleQueue(String message) {
System.out.println("消费者收到了 simple.queue 的消息:【" + message + "】");
}
}

Work Queues 模型
12.1 Work Queues 的概念
Work Queues,简单地来说,就是让多个消费者绑定到一个队列,共同消费队列中的消息
虽然有多个消费者绑定同一个队列,但是队列中的某一条消息只会被一个消费者消费
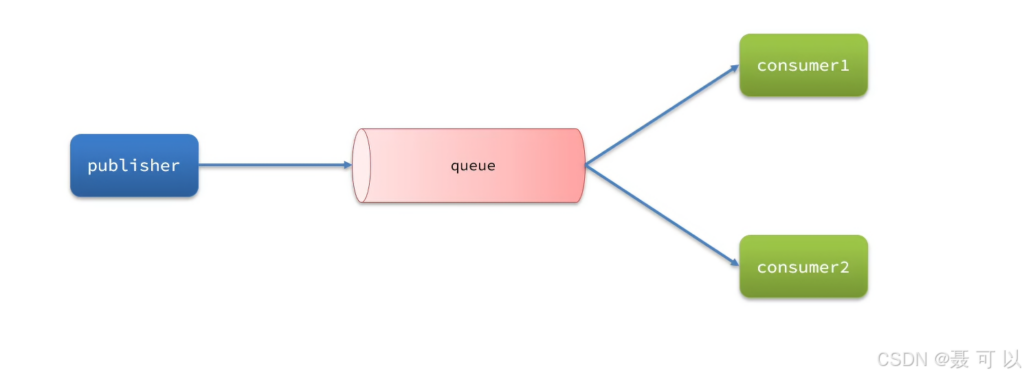
我们实现一个小案例,模拟 Work Queues,实现一个队列绑定多个消费者
案例要求如下:
在RabbitMQ的控制台创建一个队列,名为 work.queue
在 publisher 服务中定义测试方法,在 1 秒内产生 50 条消息,发送到work.queue
在 consumer 服务中定义两个消息监听者,都监听 work.queue 队列
消费者 1 每秒处理 50 条消息,消费者 2 每秒处理 5 条消息
在 publisher服务的 SpringAmqp 测试类中添加以下方法,该方法可以在 1 秒内产生 50 条消息
@Test
void testWorkQueue() throws InterruptedException {
String queueName = "work.queue";
for (int i = 1; i <= 50; i++) {
String message = "Hello, work queues_" + i;
rabbitTemplate.convertAndSend(queueName, message);
Thread.sleep(20);
}
}
在 consumer 服务的 RabbitMQListener 类中添加以下方法,监听 work.queue 队列
@RabbitListener(queues = "work.queue")
public void listenWorkQueue1(String message) {
System.out.println("消费者1 收到了 work.queue的消息:【" + message + "】");
}
@RabbitListener(queues = "work.queue")
public void listenWorkQueue2(String message) {
System.err.println("消费者2 收到了 work.queue的消息...... :【" + message + "】");
}
Work Queues 模型的消息推送机制
如果有两个或两个以上的消费者监听同一个队列,默认情况下 RabbitMQ 会采用轮询的方法将消息分配给每个队列
但每个消费者的消费能力可能是不一样的,我们给两个消费者中的代码设置不同的休眠时间,模拟消费能力的不同
@RabbitListener(queues = "work.queue")
public void listenWorkQueue1(String message) throws InterruptedException {
System.out.println("消费者1 收到了 work.queue的消息:【" + message + "】");
Thread.sleep(20);
}
@RabbitListener(queues = "work.queue")
public void listenWorkQueue2(String message) throws InterruptedException {
System.err.println("消费者2 收到了 work.queue的消息...... :【" + message + "】");
Thread.sleep(100);
}
经过测试可以发现,即使两个队列的消费能力不一样,默认情况下 RabbitMQ 还是会采用轮询的方法将消息分配给每个队列,也就是平均分配
但这不是我们想要的效果,我们想要的效果是消费能力强的消费者处理更多的消息,甚至能够帮助消费能力弱的消费者
怎么样才能达到这样的效果呢,只需要在配置文件中添加以下信息
spring:
rabbitmq:
listener:
simple:
prefetch: 1
这个配置信息相当于告诉消费者要一条一条地从队列中取出消息,只有处理完一条消息才能取出下一条
这样一来,就可以充分利用每一台机器的性能,让消费能力强的消费者处理更多的消息,同时还可以避免消息在消费能力较弱的消费者上发生堆积的情况
交换机
真正的生产环境都会经过交换机来发送消息,而不是直接发送到队列
交换机的作用:
接收 publisher 发送的消息
将消息按照规则路由到与交换机绑定的队列
交换机的类型有以下三种:
Fanout:广播
Direct:定向
Topic:话题
注意事项:交换机只能路由和转发消息,不能存储消息
Fanout 交换机
Fanout 交换机的概念
Fanout 交换机会将接收到的消息广播到每一个跟其绑定的 queue ,所以也叫广播模式
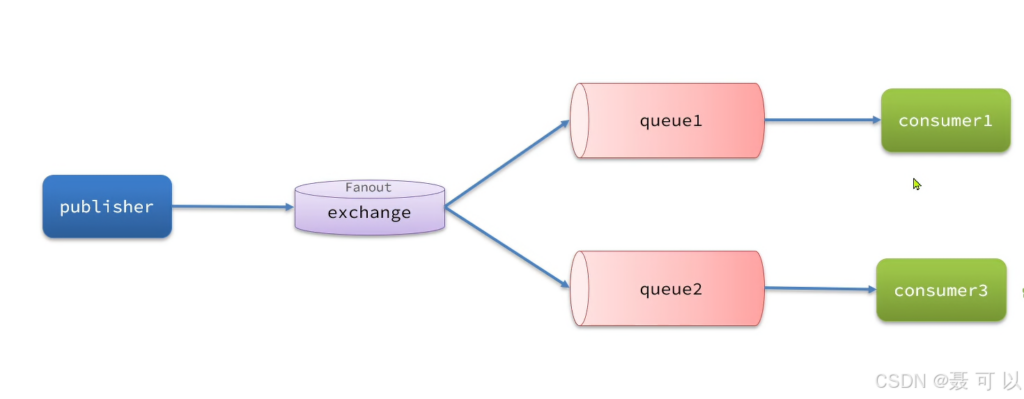
Direct 交换机
Direct 交换机的概念
Direct 交换机会将接收到的消息根据规则路由到指定的队列,被称为定向路由
每一个 Queue 都与 Exchange 设置一个 bindingKey
发布者发送消息时,指定消息的 RoutingKey
Exchange 将消息路由到 bindingKey 与消息 routingKey 一致的队列
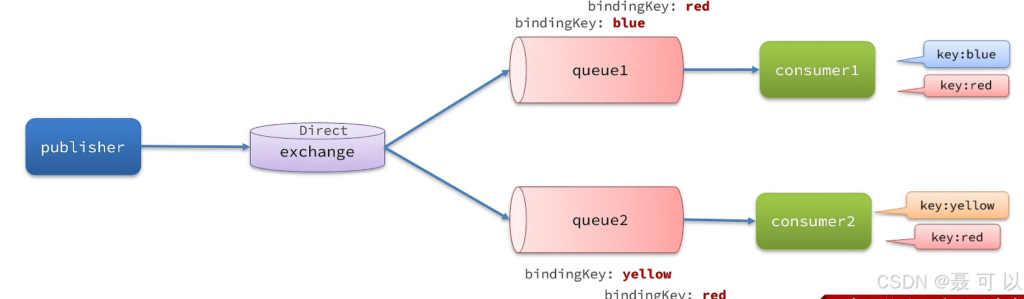
需要注意的是:同一个队列可以绑定多个 bindingKey ,如果有多个队列绑定了同一个 bindingKey ,就可以实现类似于 Fanout 交换机的效果。由此可以看出,Direct 交换机的功能比 Fanout 交换机更强大
快速上手
我们做一个小案例来体验 Direct 交换机的效果,案例要求如下:
在 RabbitMQ 控制台中,声明队列 direct.queue1 和 direct.queue2
在 RabbitMQ 控制台中,声明交换机 blog.direct ,将上面创建的两个队列与其绑定
在 consumer 服务中,编写两个消费者方法,分别监听 direct.queue1 和 direct.queue2
在 publisher 服务中编写测试方法,利用不同的 RoutingKey 向 blog.direct 交换机发送消息
为 direct.queue1队列 和 direct.queue2 队列分别指定 bindingKey
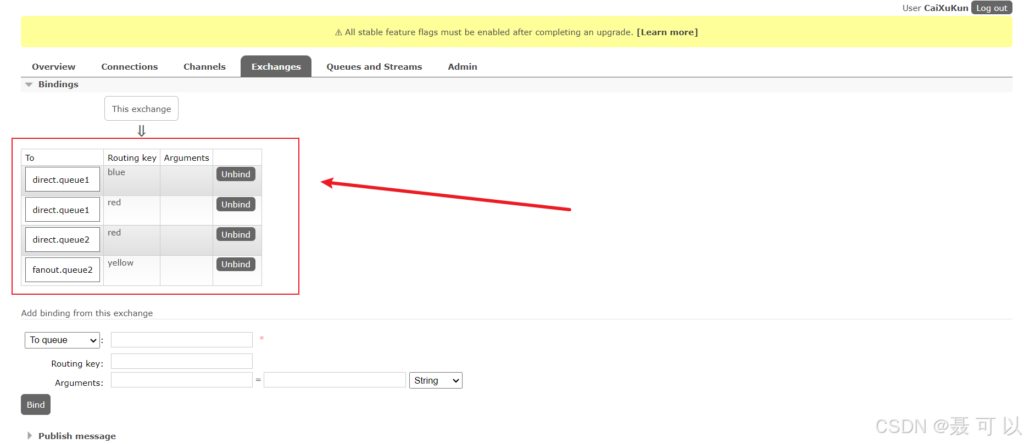
在 consumer 服务的 RabbitMQListener 类中添加以下方法,分别监听 direct.queue1 和 direct.queue2 队列
@RabbitListener(queues = "direct.queue1")
public void listenDirectQueue1(String message) {
System.out.println("消费者1 收到了 direct.queue1的消息:【" + message + "】");
}
@RabbitListener(queues = "direct.queue2")
public void listenDirectQueue2(String message) {
System.err.println("消费者2 收到了 direct.queue2的消息...... :【" + message + "】");
}
在 publisher 服务的 SpringAmqp 测试类中添加以下方法,向 blog.direct交换机发送消息
@Test
void testSendDirect() {
String exchangeName = "blog.direct";
String blueMessage = "蓝色通知,警报解除,哥斯拉放的是气球";
rabbitTemplate.convertAndSend(exchangeName, "blue", blueMessage);
String redMessage = "红色警报,由于日本排放核污水,惊现哥斯拉!";
rabbitTemplate.convertAndSend(exchangeName, "red", redMessage);
String yellowMessage = "黄色通知,哥斯拉来了,快跑!";
rabbitTemplate.convertAndSend(exchangeName, "yellow", yellowMessage);
}
Topic 交换机(推荐使用)
Topic Exchange 与 Direct Exchange类似,区别在于 Topic Exchange 的 routingKey 可以是多个单词的列表(多个 routingKey 之间以.分割)
Queue 与 Exchange 指定 bindingKey 时可以使用通配符
#:代指 0 个或多个单词
*:代指 1 个单词
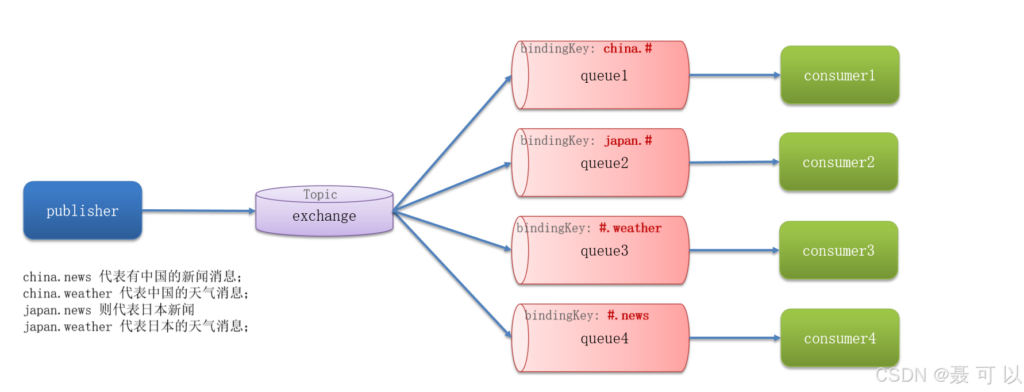
- Topic 交换机能实现的功能 Direct 交换机也能实现,不过用 Topic 交换机实现起来更加方便
- 如果某条消息的 topic 符合多个 queue 的 bindingKey ,该条消息会发送给符合条件的所有 queue ,实现类似于 Fanout 交换机的效果
在 SpringBoot 项目中声明队列和交换机的方式
我们之前创建队列和交换机都是在 RabbitMQ 的控制台页面中创建的,不仅十分繁琐,还有可能打错队列和交换机的名。而且,不同的环境(开发环境、测试环境、生产环境)可能会有不同的队列和交换机,手动创建队列和交换机效率十分低下
接下来为大家介绍两种在 SpringBoot 项目中声明队列和交换机的方式
14.1 编程式声明
SpringAQMP提供的创建队列和交换机的类
SpringAMQP 提供了几个类,用来声明队列、交换机及其绑定关系:
Queue:用于声明队列,可以用工厂类 QueueBuilder 构建
Exchange:用于声明交换机,可以用工厂类 ExchangeBuilder 构建
Binding:用于声明队列和交换机的绑定关系,可以用工厂类 BindingBuilder 构建
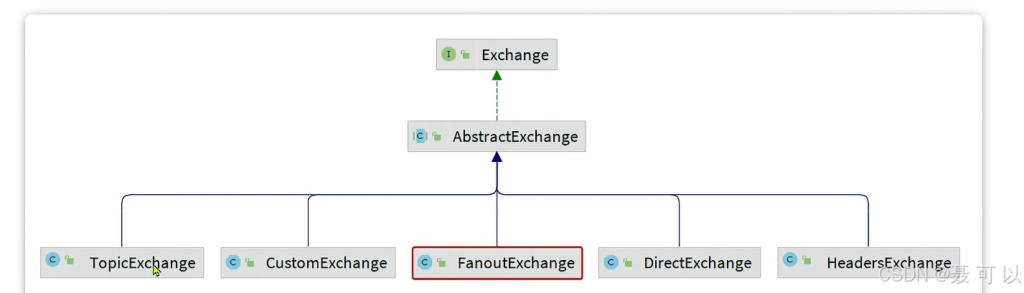
快速上手
我们创建一个 Fanout 类型的交换机,并且创建队列与这个交换机绑定
在 consumer 服务中编写 FanoutConfiguration 配置类
import org.springframework.amqp.core.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class FanoutConfiguration {
@Bean
public FanoutExchange fanoutExchange3() {
return ExchangeBuilder.fanoutExchange("blog.fanout3").build();
}
@Bean
public FanoutExchange fanoutExchange4() {
return new FanoutExchange("blog.fanout4");
}
@Bean
public Queue fanoutQueue3() {
return new Queue("fanout.queue3");
}
@Bean
public Queue fanoutQueue4() {
return QueueBuilder.durable("fanout.queue4").build();
}
@Bean
public Binding fanoutBinding3(Queue fanoutQueue3, FanoutExchange fanoutExchange3) {
return BindingBuilder.bind(fanoutQueue3).to(fanoutExchange3);
}
@Bean
public Binding fanoutBinding4() {
return BindingBuilder.bind(fanoutQueue4()).to(fanoutExchange4());
}
}
启动 consumer 的启动类之后,队列、交换机、队列和交换机之间的关系就会自动创建
创建 Queue 时,如果没有指定 durable 属性,则 durable 属性默认为 true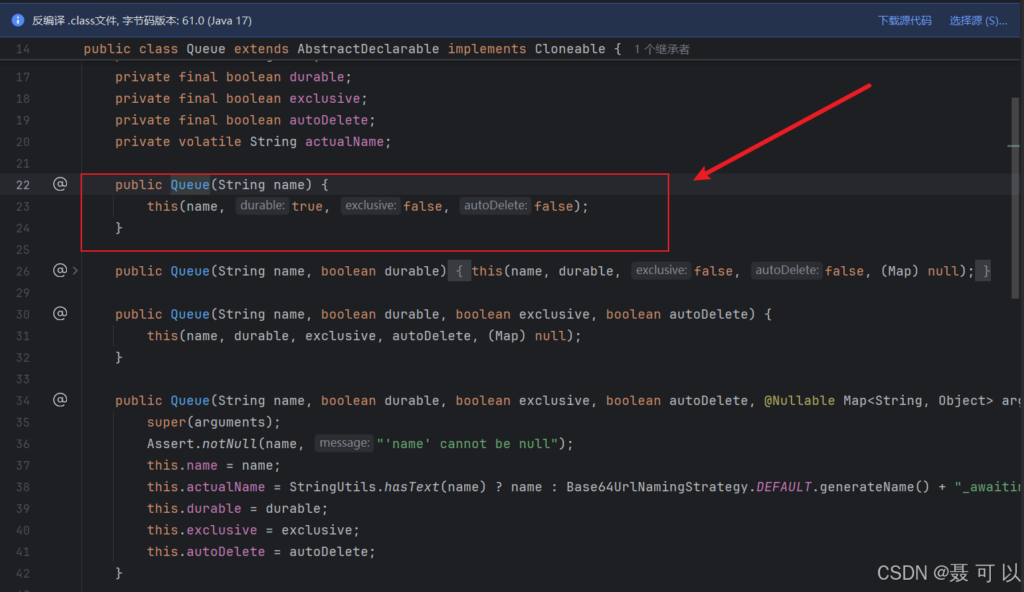
编程式声明的缺点
编程式声明有一个缺点,当队列和交换机之间绑定的 routingKey 有很多个时,编码将会变得十分麻烦
以下是一个队列与 Direct 类型交换机绑定两个 routingKey 时的代码
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.DirectExchange;
import org.springframework.amqp.core.Queue;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class DirectConfiguration {
@Bean
public DirectExchange directExchange3() {
return new DirectExchange("blog.direct3");
}
@Bean
public Queue directQueue3() {
return new Queue("direct.queue3");
}
@Bean
public Queue directQueue4() {
return new Queue("direct.queue4");
}
@Bean
public Binding directQueue3BindingRed(Queue directQueue3, DirectExchange directExchange3) {
return BindingBuilder.bind(directQueue3).to(directExchange3).with("red");
}
@Bean
public Binding directQueue3BindingBlue(Queue directQueue3, DirectExchange directExchange3) {
return BindingBuilder.bind(directQueue3).to(directExchange3).with("blue");
}
@Bean
public Binding directQueue4BindingRed(Queue directQueue4, DirectExchange directExchange3) {
return BindingBuilder.bind(directQueue4).to(directExchange3).with("red");
}
@Bean
public Binding directQueue4BindingBlue(Queue directQueue4, DirectExchange directExchange3) {
return BindingBuilder.bind(directQueue4).to(directExchange3).with("yellow");
}
}
注解式声明(推荐使用)
SpringAMOP 提供了基于@RabbitListener注解声明队列和交换机的方式

我们先在 RabbitMQ 的控制台删除 blog.direct 交换机、 direct.queue1 队列和 direct.queue2 队列
再改造 consumer 服务的 RabbitMQListener 类的监听 direct.queue1 队列和 direct.queue2 队列的方法
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue1"),
exchange = @Exchange(name = "blog.direct", type = ExchangeTypes.DIRECT),
key = {"red", "blue"}
))
public void listenDirectQueue1(String message) {
System.out.println("消费者1 收到了 direct.queue1的消息:【" + message + "】");
}
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "direct.queue2"),
exchange = @Exchange(name = "blog.direct", type = ExchangeTypes.DIRECT),
key = {"red", "yellow"}
))
public void listenDirectQueue2(String message) {
System.out.println("消费者2 收到了 direct.queue2的消息:【" + message + "】");
}
消息转换器
在了解消息转换器之前,我们先来做一个小案例,案例的内容是利用 SpringAMQP 发送一条消息,消息的内容为一个 Java 对象
案例要求如下:
在 RabbitMQ 控制台创建一个队列,名为 object.queue
编写单元测试,向该队列中直接发送一条消息,消息的内容为 Map
在控制台查看消息
在 publisher 服务的 SpringAmqpTests 测试类中新增 testSendObject 方法
@Test
void testSendObject() {
Map<String, Object> hashMap = new HashMap<>(2);
hashMap.put("name", "Tom");
hashMap.put("age", 21);
rabbitTemplate.convertAndSend("object.queue", hashMap);
}
成功发送消息后,我们在 RabbitMQ 的控制台查看消息的具体内容
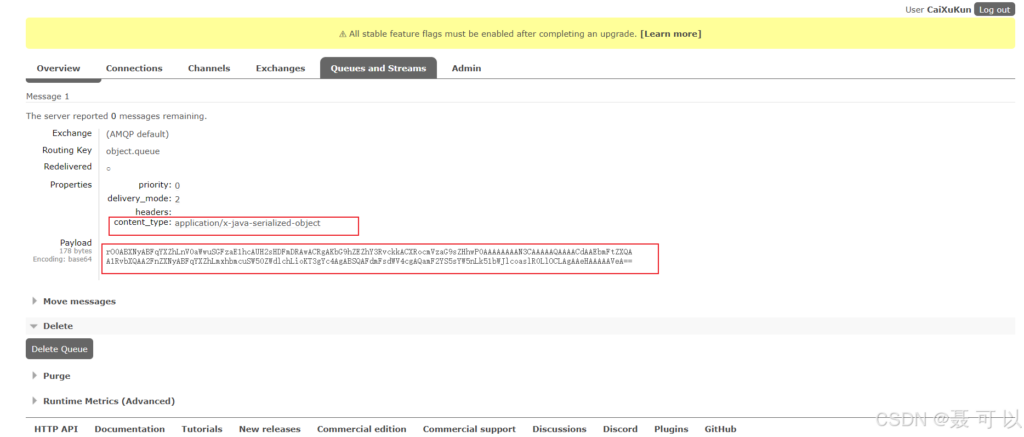
可以发现,消息的内容类型为 application/x-java-serialized-object,并且消息的内容也变成一堆乱码
我们本来是想发送一个简单的仅含有姓名和年龄两个字段的简短信息,但是消息却变成了一堆乱码,不仅可读性大大下降,而且占用的空间也大大地增加了,这显然不是我们想要的效果
默认的消息转换器
Spring 处理对象类型的消息是由 org.springframework.amap.support.converter.MessageConverter 接口来处理的,该接口默认实现是 SimpleMessageConverter
SimpleMessageConverter 类是基于 JDK 提供的 ObjectOutputStream 来类完成序列化的,这种序列化方式存在以下问题:
使用 JDK 序列化有安全风险(如果序列化后的消息被恶意篡改,在反序列化的过程中可能会执行一些高危的代码)
经过 JDK 序列化的消息占用空间很大
经过 JDK 序列化的消息可读性很差
15.2 自定义消息转换器
一般建议采用 JSON 序列化代替默认的 JDK 序列化
要使用 JSON 序列化,需要先引入 jackson 依赖(在项目的父工程中引入)
如果是 Web 项目,无需引入该依赖,因为 spring-boot-starter-web 依赖中已包含该依赖
<dependency>
<groupId>com.fasterxml.jackson.dataformat</groupId>
<artifactId>jackson-dataformat-xml</artifactId>
</dependency>
接着在 consumer 服务和 publisher 服务中配置 MessageConverter@Bean
public MessageConverter jacksonMessageConvertor(){
return new Jackson2JsonMessageConverter();
}
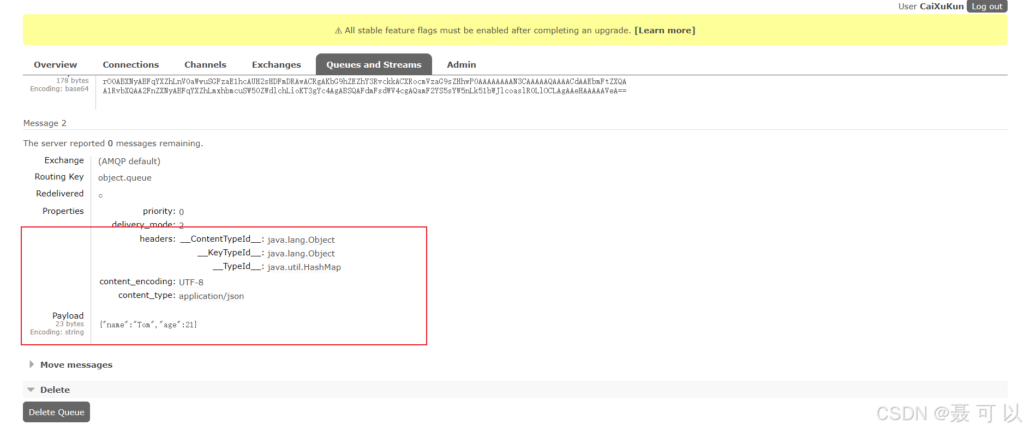
我们也可以在 consumer 服务的 RabbitMQListener 类中添加对 object.queue 队列的监听(用什么类型发,就用什么类型接收)
@RabbitListener(queues = "object.queue")
public void listenObjectQueue(Map<String, Object> hashMap) {
System.out.println("消费者收到了 object.queue的消息:【" + hashMap + "】");
}
启动 consumer 服务的启动类之后,在控制台中可以看到被转换成 JSON 格式的消息
在控制台中会看到报错信息,因为之前有一条用 JDK 序列化的消息,现在改用了 jackson 序列化,序列化和反序列化用的序列化器不一样,肯定会报错